RBMのBGSやCDやPCDってどれくらい違うのだろうか? [学問]
RBM(制約付きボルツマンマシン)のプレトレーニング(教師なし学習)の手法である、BGS(ブロック化ギブスサンプリング)やCD(コントラスティブ・ダイバージェンス法)やPCD(持続的コントラスティブ・ダイバージェンス法)について、実際の学習データを用いて、その学習の習得過程をトレースしてみた。
一般に、RBMの<vi>modelや<hi>modelや<vihj>model(注1)などは組み合わせ爆発を起こして計算することができないので、BGSを用いて計算されるが、ギブスサンプリングはバーンインに要する時間を長く取らないといけなかったりするので、計算時間が膨大になってしまう。そこで開発された時間短縮の手法が、CDやPCDと言った簡易的な手法になる。今回の実験では、BGSとCDではCD-1とCD-5の2種類とPCD(CD-1のv1の結果を次のパラメータ更新の頭で使う様にチェインで繋いでいったもの)の4種類を行っている。
データは、4ビットのバイナリーデータ(従って、16種類のデータになる)をランダムに1000個発生させて、エポック毎に10個のデータを使ってミニバッチ学習を100回行っている。入力層が4個で隠れ層が3個のRBMを構成して、パラメータは、w=(3, 4)、b=(,4)、c=(,3)としてミニバッチ学習毎に更新を行っている。パラメータ更新は、BGSはMLP深層学習(岡谷貴之著)p143の式(8.18a)〜(8.18c)を(注2)、CDはp145の式(8.19a)〜(8.19c)のアルゴリズムを用いて行っている。
図1.1〜1.3ではW(重み)の初期化を、それぞれの手法ごとでランダムな正規分布で行っている(従って4種類の手法でWの初期値は違っている)のに対して、図2.1〜2.3では全ての手法でランダムな一様分布(従って4種類の手法でWの初期値は同じ)を用いて行っている。パラメータの初期値を揃えた場合は、対数尤度、KL距離共に学習過程のバラツキは比較的小さなものになるが、違った場合のバラツキは大きくなっているのが分かる。(注3)
図1.1と図2.1は、 (式1)でエポック毎のKL(カルバック・ライブラー)距離を計算している。
DKL(P||Q) = Σi P(i)log(P(i) / Q(i)) (式1)
ここで、P(i)はデータの確率分布、Q(i)はモデルの確率分布で、Q(i)は(式2)から計算している。KL距離は、学習が進むに連れて最小値になって行っているのが分かる。
p(v | θ) = exp(Σi∈V bivi) Πj∈H (1 + exp(λj)) / Z(θ) (式2)
(ここで、λj = cj + Σ i∈V wijvi)
図1.2と図2.2は、(式3)でエポック毎の対数尤度を計算している。
LD(θ) = logΠμ=1~N p(v(μ) | θ)
= Σμ=1~N (Σi∈V bivi(μ) + Σj∈H log(1 + exp(λj(μ))) - logZ(θ)) (式3)
対数尤度は、DKLとは逆に、学習が進むに連れて、最大値になって行っているのが分かる。4つの手法が大体同じくらいの最大値で平衡した時点で学習を終了させている。
図1.3と図2.3は学習が終了した時点でのそれぞれの手法でのモデルの確率分布を示している。4つの手法ともに、実際のデータの確率分布の特徴を良く再現できている事が分かる。プレトレーニングなのでこれくらいの精度でデータの特徴を抽出できれば十分の様な気がする。
(注1)<.>は期待値を表す。
(注2)バーンインは通常は1000回以上取るのが理想だが、時間がかかり過ぎるので(これはミニバッチの度に行う必要がある)、100回で行って見たものとあまり差がなかったので100回で回している。その後ミニバッチと同じ10点をサンプリングして平均値を求めている。
(注3)一般的に、特にW(重み)の初期値によりそれぞれの手法での収束過程は上下関係なども含めて大きく変わってしまう様である。また収束にもっと時間を要してしまう様な場合もある。目安としては、対数尤度又はKL距離が最終的に全ての手法で大体同じくらいの値で収束する様な初期値を取るのがベストであると考えられるが、何れにしてもプレトレーニングなので、ある程度の回数を回して収束すればそれで良しとしても特に問題はない様に思う。
by チイ
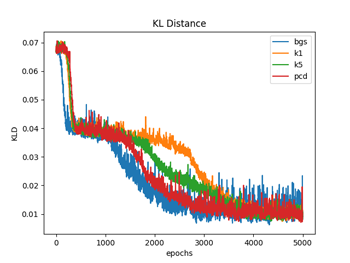 図1.1
図1.1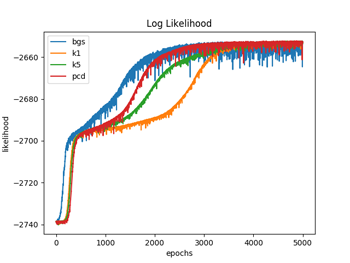 図1.2
図1.2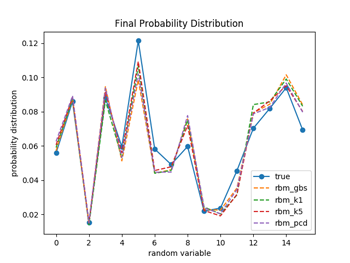 図1.3
図1.3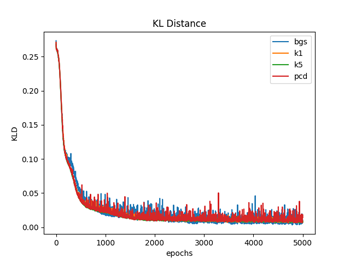 図2.1
図2.1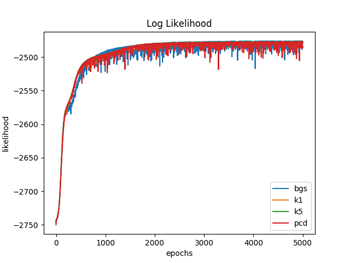 図2.2
図2.2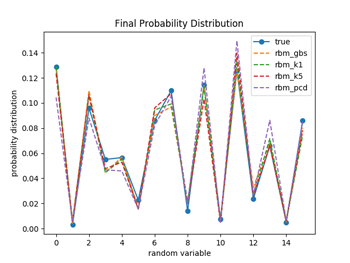 図2.3
図2.3



コメント 0